From the CTO’s Desk – November 2025: Predictive Rug Detection Using Gradient Boosting Models

Executive Overview
In October, our team analyzed malicious token contract deployments on Base and observed the same patterns repeat: risky Solidity primitives, highly concentrated early holder distributions, and sniper-driven behavior during the first moments of liquidity formation. What stood out was how early these signals appeared, well before any liquidity was actually pulled.
That insight shaped this month’s work. Rug pulls leave identifiable fingerprints in their code, their early ownership graph, and the way liquidity comes together, and those fingerprints appear early enough to be modeled.
In November, we translated those qualitative observations into a production-grade predictive system. The model combines Solidity code forensics with on-chain holder analytics and token-level features to assign a rug-probability score to each new Base token contract. It is trained on historical deployments, with heavier weighting on the most recent cohorts (e.g., October), and is currently being evaluated on November deployments to ensure it generalizes forward rather than simply memorizing the past.
The goal is straightforward: a continuously updating safety layer for Base (or any chain). It scores new token contracts as they launch, surfaces the ones that warrant human review, and shortens the detection window for bad actors operating at scale.
Why This Matters
As activity on Base accelerates, traditional security workflows simply can’t keep pace. Manual audits still matter, but they’re slow, point-in-time, and limited to the code that was handed to the auditor. They don’t reflect how liquidity forms, who actually controls the supply, how snipers behave in the first blocks, or how tokens evolve in the minutes after deployment.
One of our focuses at Webacy is to build automated, continuously updating security signals, systems that refresh every time a new contract lands on-chain or a new pattern emerges. This is where automated auditing and due diligence (DD) becomes essential. Instead of relying on static reviews that age immediately, we’re building infrastructure that reacts in real time, learns from new attack variants, and surfaces risk in near real time as it appears.
Automation doesn’t replace human expertise, it supplements it, ensuring reviewers spend their time on the contracts that truly need attention. That’s the direction we’re pushing toward: modern, scalable safety infrastructure for Base that makes it significantly harder for malicious deployments to hide in the noise.
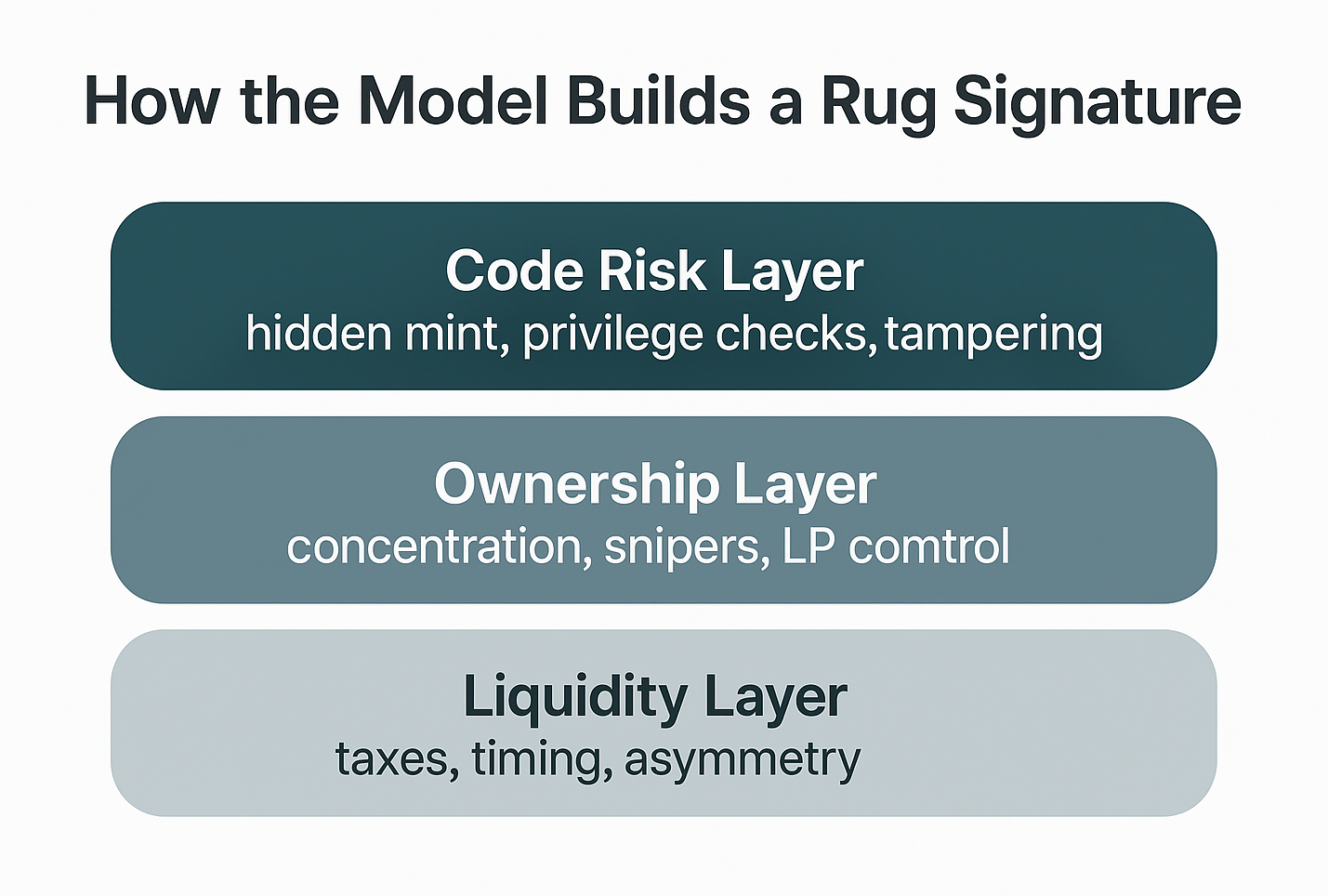
Feature Engineering
The model draws from three core categories of signals that together capture how a token is built, owned, and traded in its earliest stages.

Modeling Approach and What the Model Learns
We use tree-based gradient boosting models GBDT, XGBoost, and LightGBM because they handle mixed tabular data well, capture nonlinear interactions between features (for example, hidden mint authority combined with 95% holder concentration), and remain interpretable through feature importances and SHAP values. These models also handle varying feature scales naturally, which is essential when combining code flags, holder metrics, and liquidity signals.
Since rugs are a small fraction of all Base token deployments, we correct for class imbalance by applying class weights (GBDT) or scale_pos_weight (XGBoost, LightGBM). This improves recall on high-risk contracts without producing an excessive number of false positives.
To reflect real deployment conditions, we train on historical data with added emphasis on the most recently labeled cohorts and evaluate on early-November contracts. This time-aware validation tests whether the model can identify new rug patterns rather than simply memorize past behavior.
Across feature importances and contract examples, the model consistently picks up several dominant patterns: hidden mint paired with extreme concentration; detector saturation across exploit families; early sniper clustering and bundled trading; and upgradeability or external-call complexity, especially when combined with concentrated ownership. The takeaway is that the model does not rely on any single feature, it learns a layered signature across code risk, early ownership, liquidity formation, and trading behavior, allowing it to distinguish malicious deployments from normal ones with far greater nuance than rule-based heuristics.
Top Contributing Signals in v1
- Hidden mint + holder concentration
- Detector saturation across exploit families
- Early sniper clustering and bundling
- Upgradeability and external-call complexity
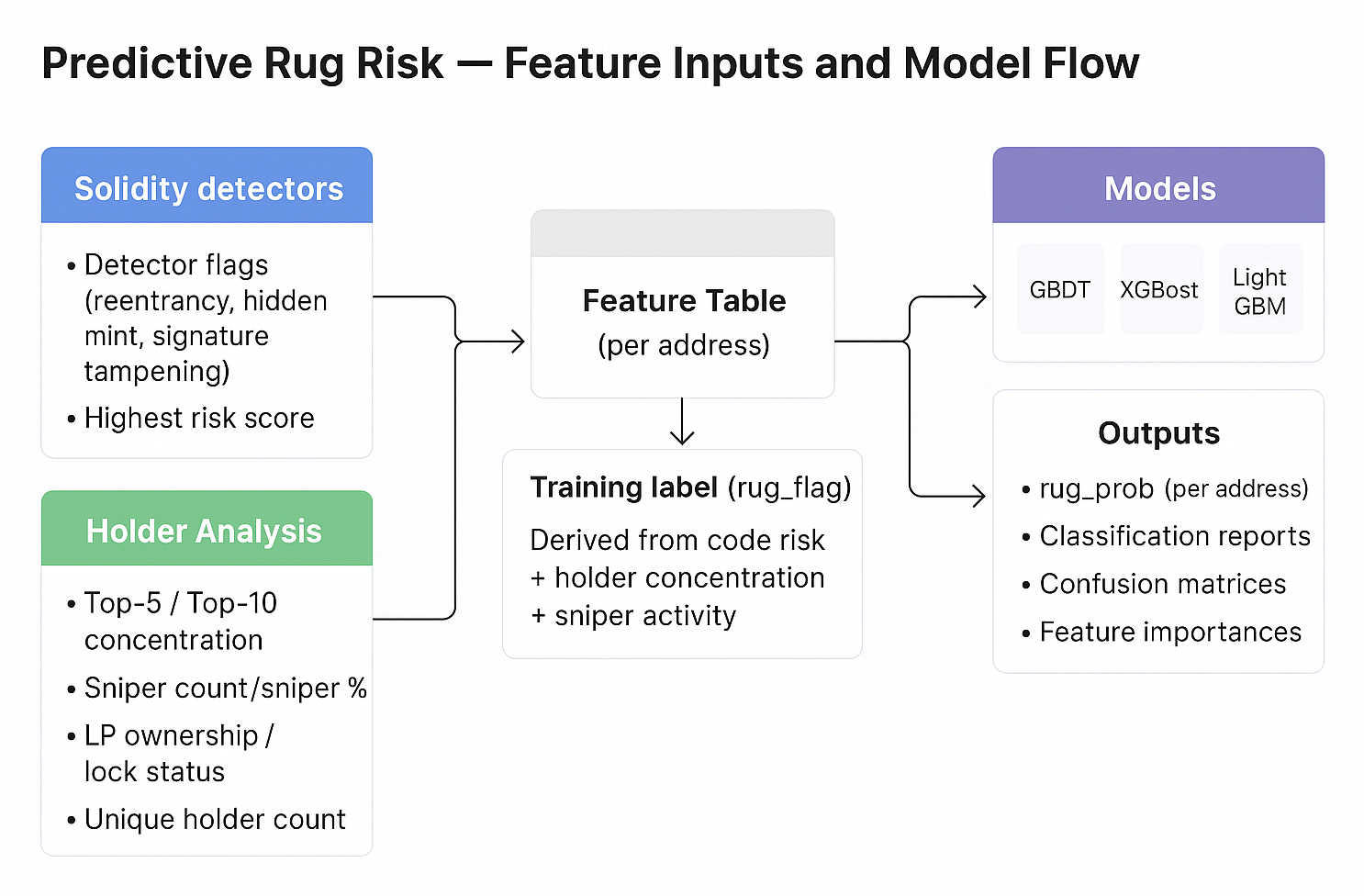
From Raw Contracts to Risk Scores
At a high level, the scoring pipeline follows a simple flow:
1. Data generation We collect new deployments, run Solidity detector analysis on verified source code, and compute holder and liquidity metrics from early on-chain activity. These signals are merged into a unified, per-address feature table.
2. Feature extractionRaw fields are normalized, typed, and aligned to the model’s schema to ensure consistent inputs across cohorts
3. Model inference The trained GBDT, XGBoost, and LightGBM models produce a rug-probability for each token, along with supporting artifacts such as classification reports, confusion matrices, and feature importances.
For readers, the v1 system diagram below summarizes this pipeline visually, showing how detector outputs and holder analytics flow into the model and how predictions and metrics come out on the other side.
Limitations and Next Steps
We’re intentionally conservative about what our v1 model can and can’t do. Attacks in Web3 evolve quickly, and improving the system ultimately comes down to reducing the number of false positives and false negatives. The next phase focuses on three areas that all contribute to that goal.
1. Better Labels and Ground Truth
We’re now incorporating more confirmed rug events, human-reviewed cases from our alerts system, delayed liquidity and loss data, and community reports. Cleaner labels give the model a clearer signal and help resolve borderline cases more reliably.
2. Higher-Quality Feature Calculations
Most of the model’s accuracy gains will come from refining the features themselves, improving how we distinguish legitimate early concentration from malicious patterns, separating organic trading from sniper activity, and adapting to new launch frameworks. We’re improving how we distinguish legitimate early concentration from malicious patterns, how we separate organic trading from sniper activity, and how we handle new launch frameworks.
We’re also tightening core calculations, LP control, delegated mint authority through proxies, normalization across ERC-20 variants, and strengthening detection across major risk categories like hidden mints, balance manipulation, reentrancy variants, unchecked calls, malicious burns, and import tampering.
3. Drift Monitoring and Continuous Adaptation
Attacker behavior changes, so the model has to continuously adapt. We’ll retrain regularly and track shifts in feature importance, calibration, and distributions across key variables like tax percentages, sniper activity, and concentration. This helps catch drift early and keeps the model effective as new rug patterns appear.
Closing Summary
This month, we turned October’s qualitative threat patterns into a fully quantitative, predictive system. The result is a supervised, explainable model that assigns a rug-pull probability to new token contracts from the earliest stages of deployment, using code-level features immediately and incorporating holder and liquidity behavior as soon as it forms.
The model is grounded in real malicious patterns and transparent in how it uses code, holder, and tokenomics features, and operational in scoring new deployments every day. It is also built to evolve, incorporating richer behavioral, temporal, and tax-based signals as the threat landscape changes.
Our goal remains the same: make rug-style attacks expensive, detectable, and ultimately unprofitable. By surfacing risk early, reducing false positives and false negatives, and adapting to new attack variants, we’re making it far harder for malicious contracts to hide in Base’s (or any blockchain’s) high-volume deployment flow and giving users, wallets, and protocols a stronger layer of protection.